随着网络爬虫的应用越来越多,互联网中涌现了一些网络爬虫框架,这些框架将网络爬虫的一些常用功能和业务逻辑进行了封装。在这些框架的基础上,我们只需要按照需求添加少量代码,就可以实现一个网络爬虫。Scrapy是目前比较流行的Python网络爬虫框架之一,可以帮助开发人员高效地开发网络爬虫程序。
简介
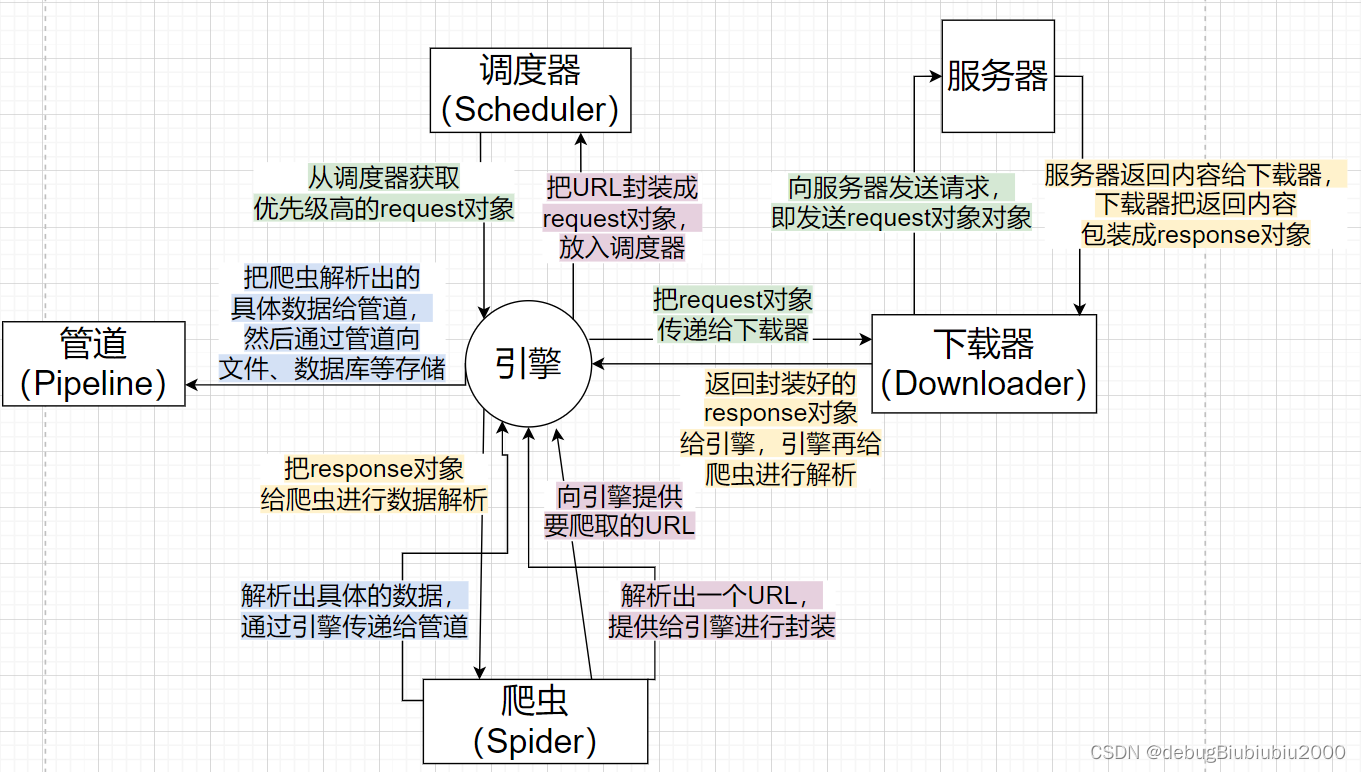
Scrapy 架构
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,去重,入队,当引擎需要时,交还给引擎。Downloader(下载器): 负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。**Spider(爬虫): **它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道): 它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。**Downloader Middlewares(下载中间件): **一个可以自定义扩展下载功能的组件。
Spider Middlewares(爬虫中间件): 一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
新建项目 创建一个新的Scrapy项目
1 scrapy startproject 项目名称
这个例子下我们将项目名称设为:mySpider
可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:
下面来简单介绍一下各个主要文件的作用:
mySpider/
scrapy.cfg
mySpider/
init .py
items.py
pipelines.py
settings.py
spiders/
init .py
这些文件分别是:
scrapy.cfg: 项目的配置文件。 mySpider/: 项目的Python模块,将会从这里引用代码。 mySpider/items.py: 项目的目标文件。 mySpider/pipelines.py: 项目的管道文件。 mySpider/settings.py: 项目的设置文件。 mySpider/spiders/: 存储爬虫代码目录。
进入项目 cd balala...
创建爬虫 修改spiders下新建的py文件 打开 mySpider/spider目录里的 itcast.py,默认增加了下列代码:
1 2 3 4 5 6 7 8 9 10 11 import scrapyclass ItcastSpider (scrapy.Spider): name = "itcast" allowed_domains = ["itcast.cn" ] start_urls = ( 'http://www.itcast.cn/' , ) def parse (self, response ): pass
name = “” :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
allow_domains = [] 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
start_urls = () :爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
处理翻页
1 start_urls = [f'https://movie.douban.com/top250?start={i} &filter=' for i in range (0 , 250 , 25 )]
parse(self, response) :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item) 生成需要下一页的URL请求。
不 使用Scrapy的Item类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import scrapyclass ItcastSpider (scrapy.Spider): name = 'itcast' allowed_domains = ['itcast.cn' ] start_urls = ['https://www.itheima.com/teacher.html#apython' ] def parse (self, response ): Items = [] teacherlist = response.xpath("//div[@class='li_txt']" ) for teacher in teacherlist: item = {} name = teacher.xpath("./h3/text()" ).extract() title = teacher.xpath("./h4/text()" ).extract() info = teacher.xpath("./p/text()" ).extract() item['名字' ] = name item['头衔' ] = title item['简介' ] = info Items.append(item) return Items
使用Scrapy的Item类 在 mySpider/items.py 里定义了一个 ItcastItem 类
1 2 3 4 5 6 7 import scrapyclass ItcastItem (scrapy.Item): name = scrapy.Field() title = scrapy.Field() info = scrapy.Field()
修改 itcast.py 文件代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from mySpider.items import ItcastItemdef parse (self, response ): items = [] for each in response.xpath("//div[@class='li_txt']" ): item = ItcastItem() name = each.xpath("h3/text()" ).extract() title = each.xpath("h4/text()" ).extract() info = each.xpath("p/text()" ).extract() item['name' ] = name[0 ] item['title' ] = title[0 ] item['info' ] = info[0 ] items.append(item) return items
通过items.py修改item类 在 Scrapy 中,Item 是一个简单的容器,用于保存抓取的数据,类似于字典,但是提供了额外的保护机制来避免拼写错误等常见问题。
Scrapy Item 和 .Field() 解释
Item 定义 :scrapy.Item。在类中,你使用 .Field() 方法来声明每个字段。字段声明 :.Field() 方法用于在 Item 类中声明一个字段。它实际上并不执行任何操作,但它告诉 Scrapy 该字段是 Item 的一部分。这样做的好处是,当你尝试向 Item 中添加一个未声明的字段时,Scrapy 会抛出一个 KeyError,这有助于你发现可能的拼写错误或逻辑错误。示例 :
1 2 3 4 5 6 import scrapyclass ArticleItem (scrapy.Item): title = scrapy.Field() author = scrapy.Field() body = scrapy.Field()
在这个例子中,ArticleItem 类有三个字段:title、author 和 body。这些字段用于存储抓取到的文章数据。
使用 Item :
1 2 3 4 5 6 7 8 from mySpider.items import ArticleItem... def parse (self, response ): article = ArticleItem() article['title' ] = response.xpath('//h1/text()' ).get() article['author' ] = response.xpath('//span[@class="author"]/text()' ).get() article['body' ] = response.xpath('//div[@class="body"]/text()' ).getall() yield article
在这个例子中,parse 方法是爬虫的一个解析方法,它负责解析网页并提取数据。它创建了一个 ArticleItem 实例,并使用 XPath 选择器从响应中提取数据来填充字段。
.Field() 在 Scrapy 中用于在 Item 类中声明字段,它提供了一种机制来确保你只能向 Item 中添加预定义的字段,从而避免了可能的拼写错误和逻辑错误。在定义 Item 时,你通常会为每个你想要抓取的数据项声明一个字段,并在爬虫中使用这些字段来存储数据。
在pipeline使用 pipeline中常用的方法:
process_item(self,item,spider):
管道类中必须有的函数
实现对item数据的处理
必须return item
open_spider(self, spider): 在爬虫开启的时候仅执行一次
close_spider(self, spider): 在爬虫关闭的时候仅执行一次
注意点
使用之前需要在settings中开启
1 2 3 4 5 6 ...... ITEM_PIPELINES = { 'myspider.pipelines.ItcastFilePipeline' : 400 , 'myspider.pipelines.ItcastMongoPipeline' : 500 , } ......
pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过:权重值小的优先执行
有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
pipeline中process_item的方法必须有,否则item没有办法接受和处理
process_item方法接受item和spider,其中spider表示当前传递item过来的spider
open_spider(spider) :能够在爬虫开启的时候执行一次
close_spider(spider) :能够在爬虫关闭的时候执行一次
上述俩个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
示例 以下代码来源于网络
分别将图片保存到本地、保存到 MySQL 数据库和保存到 MongoDB 数据库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 import pymysqlimport pymongofrom scrapy import Requestfrom scrapy.pipelines.images import ImagesPipelinefrom scrapy.exceptions import DropItemclass MongoPipeline : def __init__ (self, mongo_uri, mongo_db ): self .mongo_uri = mongo_uri self .mongo_db = mongo_db @classmethod def from_crawler (cls, crawler ): return cls(mongo_uri=crawler.settings.get("MONGO_URI" ), mongo_db=crawler.settings.get("MONGO_DB" )) def open_spider (self, spider ): self .client = pymongo.MongoClient(self .mongo_uri) self .db = self .client[self .mongo_db] def process_item (self, item, spider ): print (item) name = item.collection self .db[name].insert_one(dict (item)) return item def close_spider (self, spider ): self .client.close() class MysqlPipeline : def __init__ (self, host, database, user, password, port ): self .host = host self .database = database self .user = user self .password = password self .port = port @classmethod def from_crawler (cls, crawler ): return cls( host=crawler.settings.get("MYSQL_HOST" ), database=crawler.settings.get("MYSQL_DATABASE" ), user=crawler.settings.get("MYSQL_USER" ), password=crawler.settings.get("MYSQL_PASSWORD" ), port=crawler.settings.get("MYSQL_PORT" ), ) def open_spider (self, spider ): print (1111 ) self .db = pymysql.connect(host=self .host, user=self .user, password=self .password, database=self .database, charset="utf8" , port=self .port) self .cursor = self .db.cursor() def close_spider (self, spider ): self .db.close() def process_item (self, item, spider ): print (item["title" ]) data = dict (item) keys = ", " .join(data.keys()) values = ", " .join(['%s' ] * len (data)) sql = "insert into %s (%s) values (%s)" % (item.table, keys, values) self .cursor.execute(sql, tuple (data.values())) self .db.commit() return item class TupianspiderPipeline (ImagesPipeline ): def file_path (self, request, response=None , info=None , *, item=None ): url = request.url file_name = url.split("/" )[-1 ] print (file_name) return file_name def item_completed (self, results, item, info ): images_paths = [x['path' ] for ok, x in results if ok] print (images_paths) if not images_paths: raise DropItem("Image Download Failed" ) return item def get_media_requests (self, item, info ): print (item["url" ]) yield Request(item["url" ])
存入csv 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import pymysql class GamePipeline : def __init__ (self ): self .f = None def open_spider (self, spider ): """""" print ('爬虫开始了...' ) self .f = open ('./game_data.csv' , mode='a' , encoding='utf-8' ) def process_item (self, item, spider ): """ 接收爬虫通过引擎传递过来的数据 :param item: 具体的数据内容 :param spider: 对应传递数据的爬虫程序 :return: """ print ('爬虫进行中...' ) self .f.write(f'{item["category" ]} , {item["name" ]} , {item["date" ]} \n' ) return item def close_spider (self, spider ): print ('爬虫结束了...' ) if self .f: self .f.close()
存入mysql 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 from game.settings import MYSQLclass GameMySqlPipeline : def __init__ (self ): self .conn = None def open_spider (self, spider ): print ('爬虫开始了...' ) self .conn = pymysql.connect( host=MYSQL['host' ], port=MYSQL['port' ], user=MYSQL['user' ], password=MYSQL['password' ], database=MYSQL['database' ] ) def process_item (self, item, spider ): """ 接收爬虫通过引擎传递过来的数据 :param item: 具体的数据内容 :param spider: 对应传递数据的爬虫程序 :return: """ print ('爬虫进行中...' ) try : cursor = self .conn.cursor() insert_sql = 'insert into 数据库表名 (字段1, 字段2, 字段3, ...) values (%s, %s, %s)' cursor.execute(insert_sql, (item['category' ], item['name' ], item['date' ])) self .conn.commit() except : self .conn.rollback() finally : if cursor: cursor.close() return item def close_spider (self, spider ): print ('爬虫结束了...' ) if self .conn: self .conn.close()
setting修改 头部伪装 1 2 3 4 5 DEFAULT_REQUEST_HEADERS = { "Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8" , "Accept-Language" : "en" , "User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident / 5.0;" }
修改中文编码 1 FEED_EXPORT_ENCODING = "utf-8-sig"
将pipline进行生效设置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ITEM_PIPELINES = { # 管道程序的所在路径:优先级 # 300 表示管道的优先级,数字越小优先级越高 # 优先级高的管道会比优先级低的管道先拿到数据 "game.pipelines.GamePipeline": 300, # 优先级比GamePipeline高,可以通过运行结果看出 "game.pipelines.OtherPipeline": 299 } # 配置MySQL MYSQL = { "host": "localhost", # 主机 "port": 3306, # 端口 "user": "xxx", # 用户名 "password": "xxx", # 密码 "database": "xxx" # 数据库名称 }
运行爬虫 以…文件导出 例如
scrapy crawl itcast -o teacher.csv
1 scrapy crawl 爬虫名 -o 导出的文件名.文件格式的后缀名
其他问题 为什么使用 yield 而不是 return?
异步处理 :yield 允许 Scrapy 在解析函数执行期间“暂停”并继续处理其他请求或任务,一旦有数据可用或网络响应返回,Scrapy 就会“恢复”解析函数的执行。这与传统的同步代码中使用 return 立即返回结果的方式截然不同。产生多个Item :yield 可以逐个产生这些Item,而不是一次性返回一个包含所有Item的列表。这样做的好处是,Scrapy 可以更有效地管理内存和并发,因为它可以按需处理每个Item,而不必一次性加载整个页面上的所有数据。事件驱动的架构 :yield 允许 Scrapy 在这些事件发生时动态地产生新的请求或Item,而不是依赖于函数返回值来传递数据。链式处理 :yield 可以轻松地在这些解析函数之间传递数据和控制流,而无需显式地管理状态或回调。符合Python生成器协议 :yield 关键字在Python中用于创建生成器,这是一种特殊的迭代器,它允许你按需产生序列中的元素,而不是一次性创建整个序列。Scrapy 利用这一点来高效地处理大量数据,避免不必要的内存消耗。
示例解释 在以下示例中,parse 方法使用 yield 来逐个产生 ArticleItem 对象:
1 2 3 4 5 6 7 def parse (self, response ): for article_selector in response.css('article' ): article = ArticleItem() article['title' ] = article_selector.css('h1::text' ).get() article['author' ] = article_selector.css('span.author::text' ).get() article['body' ] = article_selector.css('div.body::text' ).getall() yield article
如果在这个方法中使用 return,那么它将只能返回一个单一的Item或请求,并且会立即结束方法的执行。这与Scrapy期望的异步和事件驱动的处理方式不符。
综上所述,使用 yield 而不是 return 是Scrapy框架设计的一个关键方面,它允许Scrapy以高效、异步和事件驱动的方式处理大量数据和网络请求。